What counts in life is not the mere fact that we have lived. It is what difference we have made to the lives of others that will determine the significance of the life we lead.

Timeline pic from Timelinemaker where the featured timeline was Nelson Rolihlahla Mandela
Background
I recently applied for admission into an online Masters in Analytics at a US university. As part of the process I needed to submit my CV. I used Nicholas Strayer’s {datadrivencv} to create the CV I submitted.
But I am a bit embarrassed at putting my own CV into the public domain, so I thought I would create a
There are no words for what Madiba did for my country, I still remember mourning his death like that of a dearest loved one, so foundational was he in this ordinary South African’s life.
So, what are we doing?
We’re going to run through the motions of setting up a CV using the {datadrivencv} 📦.
Download {datadrivencv} 📦
install.packages("devtools")
devtools::install_github("nstrayer/datadrivencv")
Set-up data
The data is housed within a google sheet, or alternately you can generate csv’s from an Excel workbook / Googlesheet to hold your data.
We’re going to use the google sheet method since it is the easiest and cleanest.
Google Sheet Method
Instead of starting from scratch, as Nicholas says in the documentation, you can create a copy of this data and amend it to suit your needs.
Google Sheet Amendments
Amend your google sheet copy as you need.
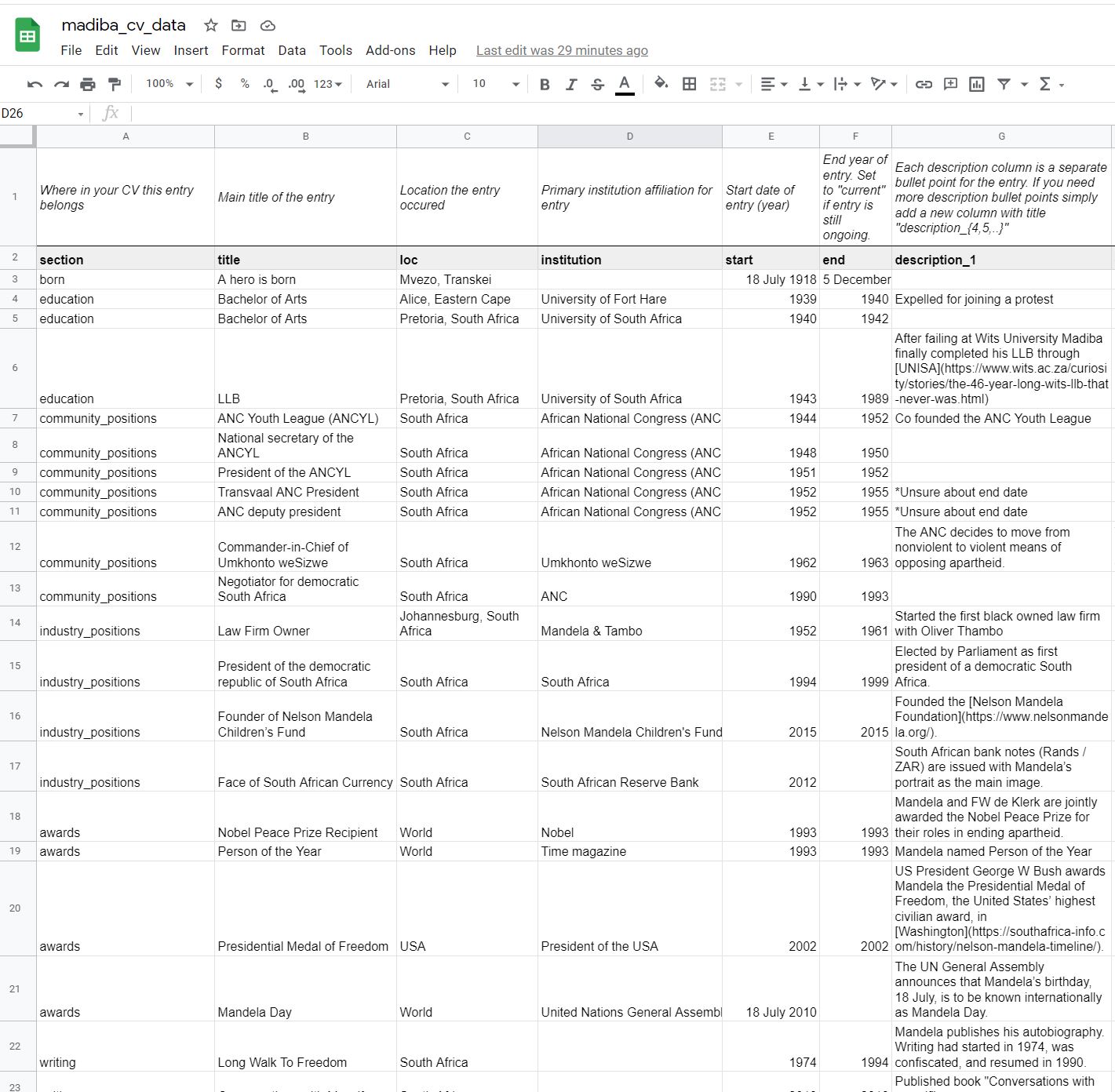
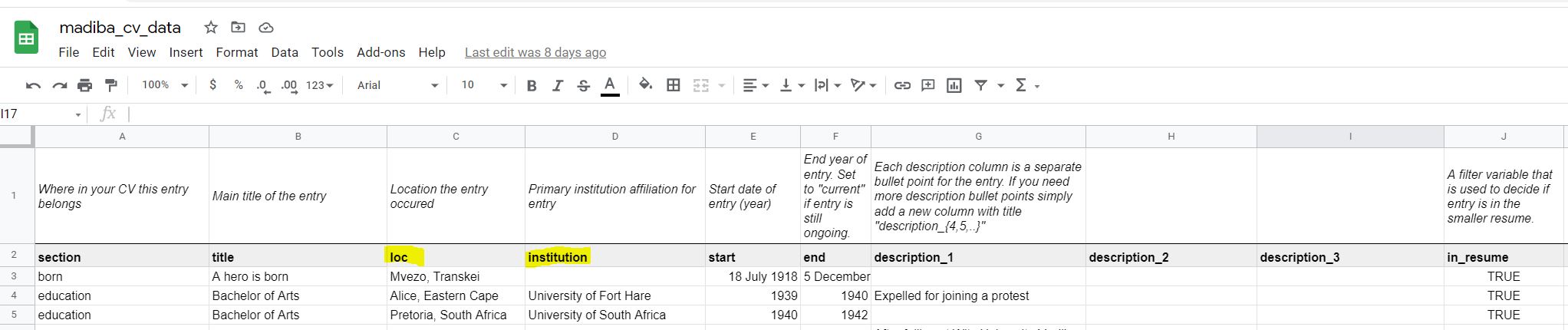
Entries Sheet
I removed certain sections, and added a born, community_positions and awards section.
I renamed data_science_writings to writing.
Here is what my entries sheet looks like after my changes.
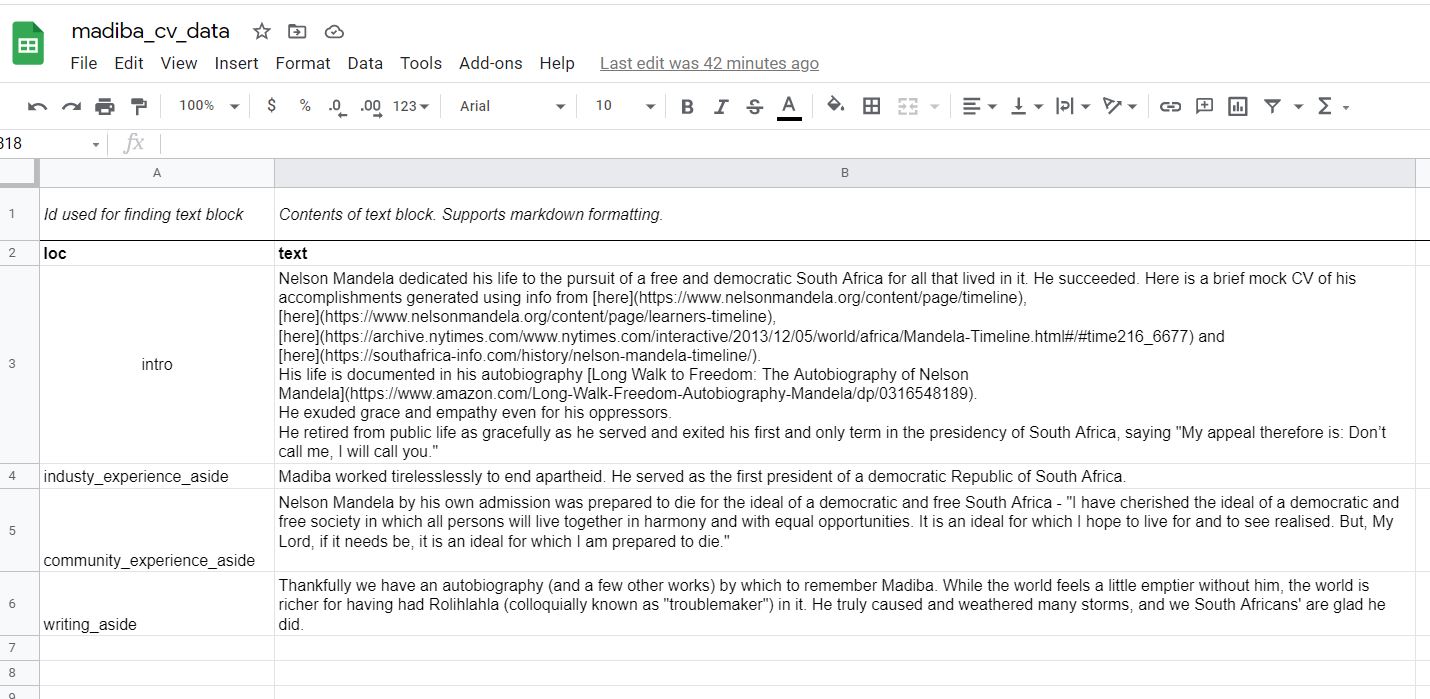
Text Blocks Sheet
You may also want to include different aside(s) in your CV. These are specified in the text_blocks sheet of the google sheets document.
Here is what my text_blocks sheet looks like after my changes. The aside(s) are tailored to the sections I have included on the entries sheet.
Contact and Languages
These are the other 2 sheets which need to be personalised with your info.
Create skeleton project
Create a folder in an appropriate location on your machine, which will house the files of your CV.
I like working in an R project. If you’d like to do the same, open RStudio, and create a project in that “Existing folder” you created in step 1 (File -> New Project -> Existing Directory)
Run something similar to the below in your console window, after replacing the names with yours, and also replacing the
data_locationwith the location of where your data is housed (i.e. the URL of your copy of the google sheet data).datadrivencv::use_datadriven_cv( full_name = "Nelson Mandela", data_location = "https://docs.google.com/spreadsheets/d/1_6fzNA6MwDSjUBXjjV7ThJfKEYj8xxJO9i09IV1cVVY/edit#gid=917338460", pdf_location = here::here("nelson-mandela.pdf"), html_location = here::here(), source_location = here::here() )- This creates a few files in your folder, the most important ones being
cv.rmd,cv_printing_functions.randrender_cv.r. cv.rmdcontains the flow of your CV, this is the file which you amend as you need, for example, if I wanted to add a Community Building section I would do so in this file.cv_printing_functions.rcontains the code to print your CV. This is generally not amended, but I did make a few amendments which I will show in the course of the tutorial.render_cv.rrenders both the html and pdf versions of your CV when it is run (sourced).
- This creates a few files in your folder, the most important ones being
cv.rmd
In cv.rmd you will set out the flow of your CV.
Here, for example is where I added the
Bornsection, and any other sections which were particular to myentriessheet.Born {data-icon=superpowers data-concise=true} -------------------------------------------------------------------------------- ```{r} CV %<>% print_section('born') ```I also amended certain sections I had re-named. All in all this should talk to your entries sections, and the text_blocks names (stored in column
loc) for your asides.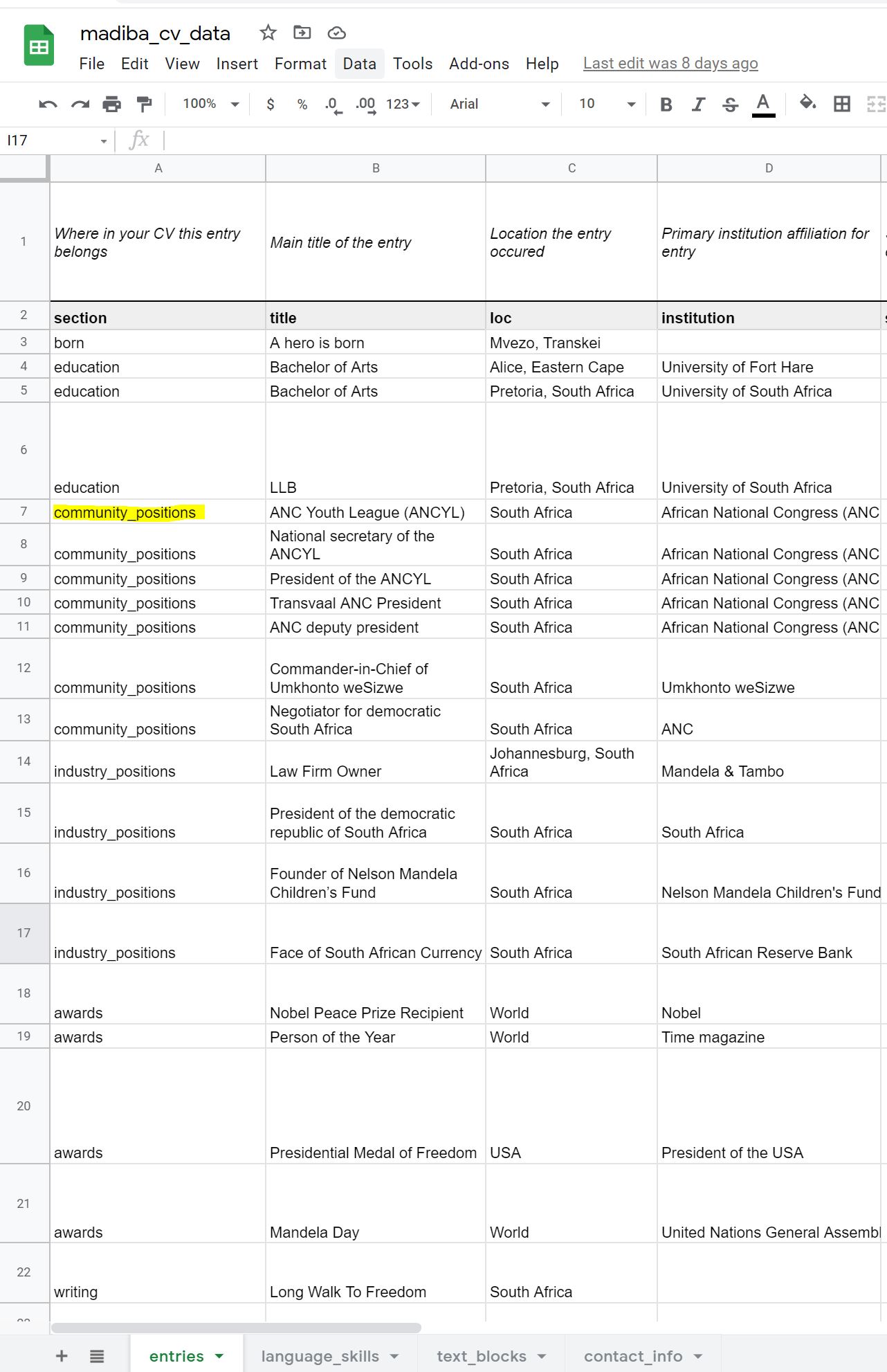
Figure 4 - My Google Sheet entries for the community_positions section

Figure 5 - My Google Sheet text_blocks for the community_positions section
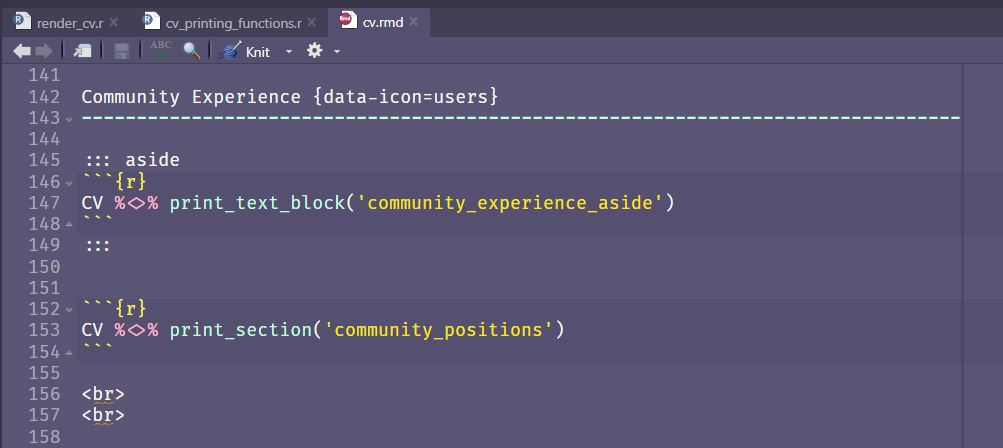
Figure 6 - The “Community Experience” section in the cv.rmd file
Some other things you might want to do here is change the data-icon part. For example, I wanted a superhero icon for the
Bornsection so I searched fontawesome for something like that. It doesn’t work all the time, and I have not dug into the reason behind why some icons are not rendering. For example, searching for hero gives the option of amaskbut makingdata-icon=maskdoes not render.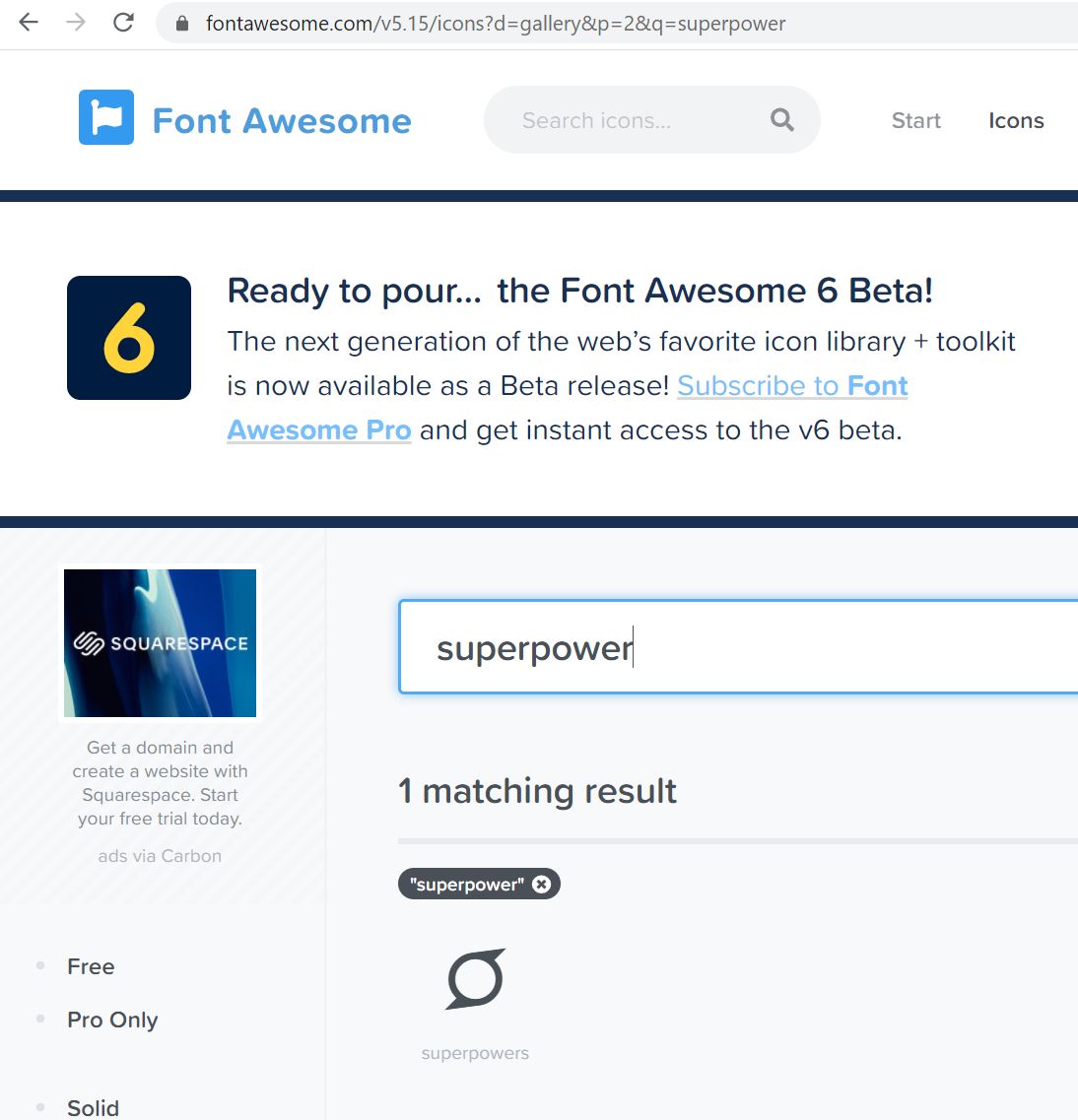
Figure 7 - fontawesome search for “superpower”
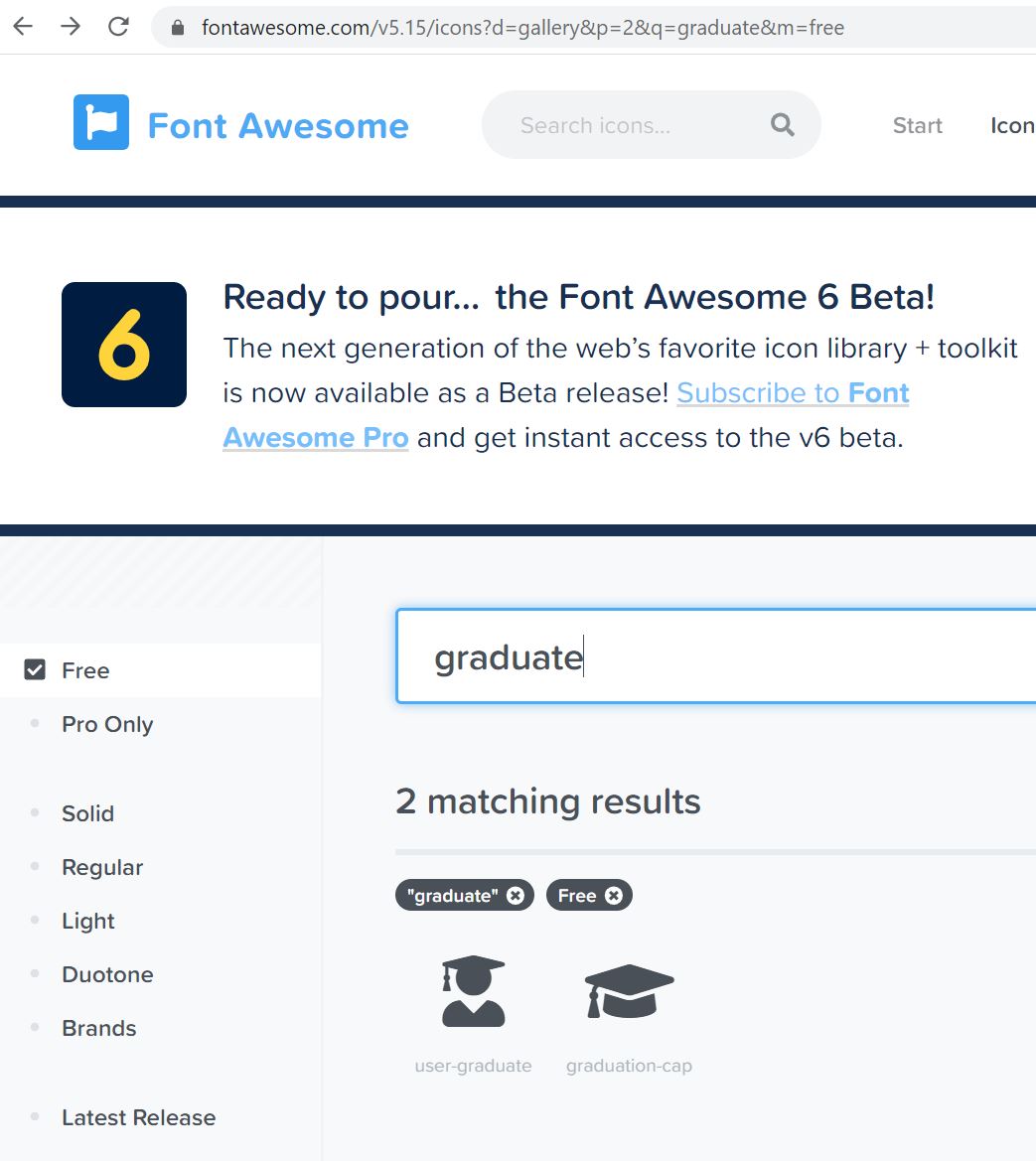
Figure 8 - fontawesome search for “graduate”
You may need to add line breaks to align your CV nicely. To do this add a
<br>in the cv.rmd file to space sections out to your liking.<br> <br>
cv_printing_functions.r
There is not much to do in this file. If you want to keep your Google sheet private there is something you need to do, but we’ll get into that later.
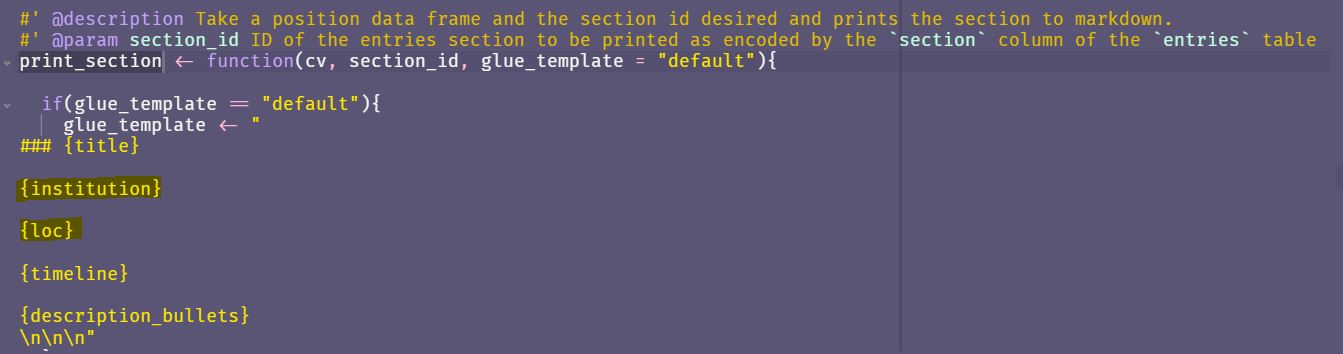
In Nick’s data you will see that the loc column contains the university or company, and the institution column contains the actual physical place.
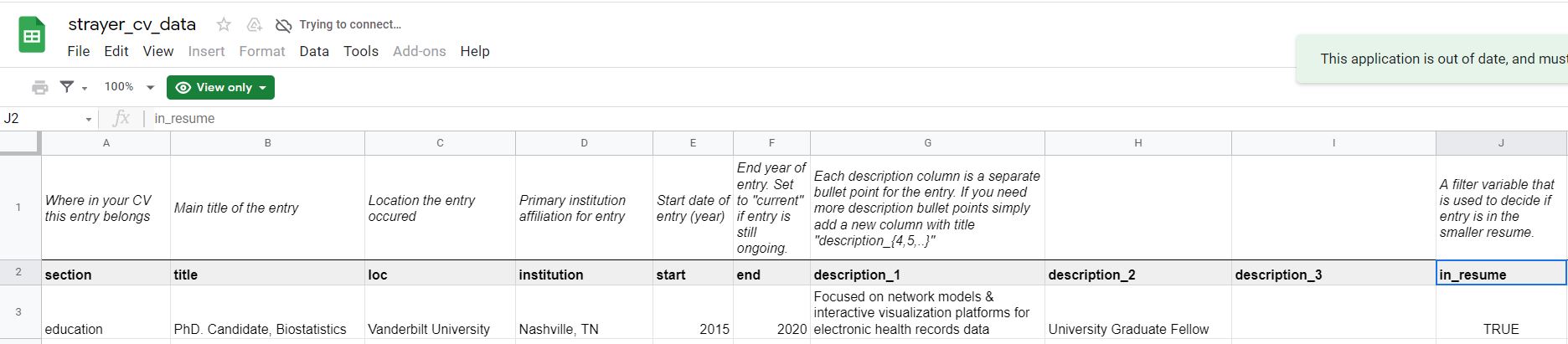
I did it the opposite, that is, for loc I captured the physical place on earth, whereas institution I captured ANC etc.
So I needed to amend the print_section() function in this file. I switched the {loc} and {institution} positions in the glue_template.
Data for CV
The data for the CV may be housed in:
- A private Google Sheet file
- A public Google Sheet file
- csv files on your local machine
Working with a Private Google Sheets File in R
You may prefer to keep your google sheet file private, and not have it publicly available for everyone to see.
In this case we need to authenticate for the R session.
googlesheets4::gs4_auth(email = "test@gmail.com")A new window will open in the browser asking you to allow “Tidyverse API Packages”, or similar, access to your Google Account. Allow the access so that you may read the google sheets in your R session.
In the R session you will be asked if information must be cached to
a/certain/path/in/your/local/machine. I said yes to mine and set my options in thecv_printing_functions.rfile to the cache specified, as follows:options( gargle_oauth_cache = "C:/Users/vebashini/.R/gargle/gargle-oauth" )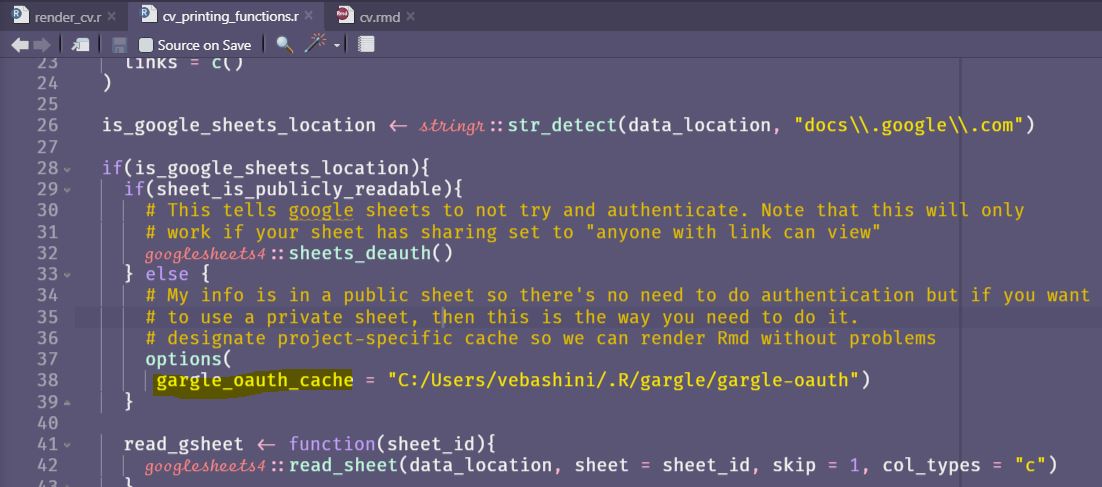
Figure 12 - Authentication cache in cv_printing_functions.r
In the
cv.rmd file only thepdf_modeparameter is present, but since we are keeping the Google sheet private we need to add another parametersheet_is_publicly_readableand set it to false.params: pdf_mode: value: true sheet_is_publicly_readable: value: false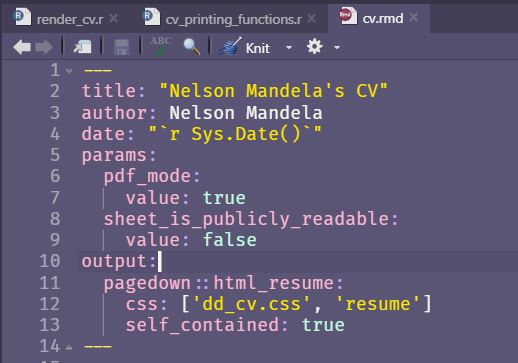
Figure 13 -
sheet_is_publicly_readableParameter needed in the cv.rmd fileWe want to pass this parameter into the
create_CV_object()function so we amend it as well.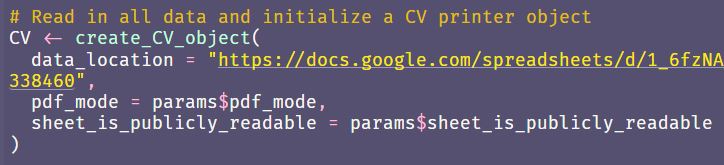
Figure 14 - Parameter needed in the
create_CV_object()function too
Working with a Public Google Sheets File in R
If you’re okay to keep your Google Sheet public you need to Share your sheet by specifying that “Anyone with the link” may View the google sheet.
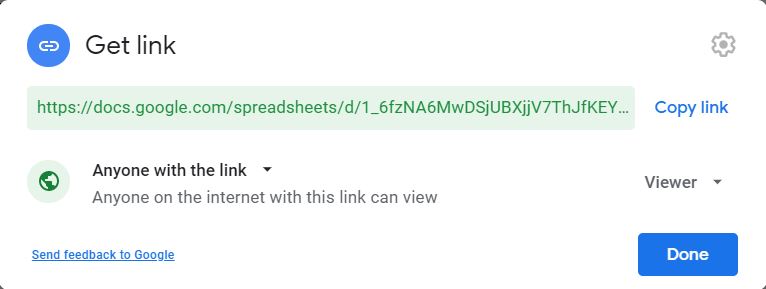
There is no need to add the sheet_is_publicly_readable to your parameter list in cv.rmd.
The sheet_is_publicly_readable parameter is TRUE by default and hence the googlesheets4::sheets_deauth() will be run.
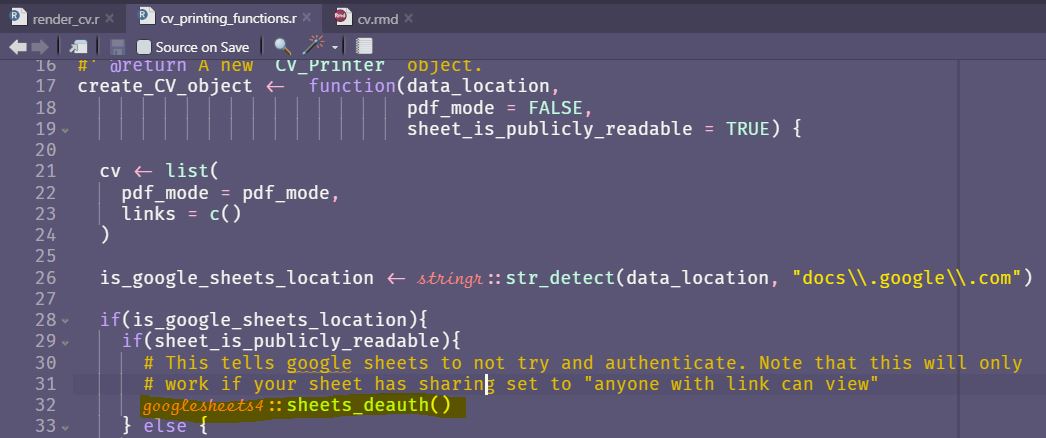
Working with csvs
If you want you can also download the Google sheet data as an Excel file on your machine and amend it there.
To create csvs from the Excel file you can run something like this:
library(readxl)
library(readr)
entries <- read_xlsx("csvs/madiba_cv_data.xlsx", sheet = 1)
language <- read_xlsx("csvs/madiba_cv_data.xlsx", sheet = 2)
text_blocks <- read_xlsx("csvs/madiba_cv_data.xlsx", sheet = 3)
contact <- read_xlsx("csvs/madiba_cv_data.xlsx", sheet = 4)
write_csv(entries, "csvs/entries.csv")
write_csv(language, "csvs/language_skills.csv")
write_csv(text_blocks, "csvs/text_blocks.csv")
write_csv(contact, "csvs/contact_info.csv")
The Google Sheets method is better because every amendment you make on the Excel workbook will mean re-running this code 😨!
You will also need to make the data_location argument in the create_CV_object() (in cv.rmd) be the folder where your csvs are located.
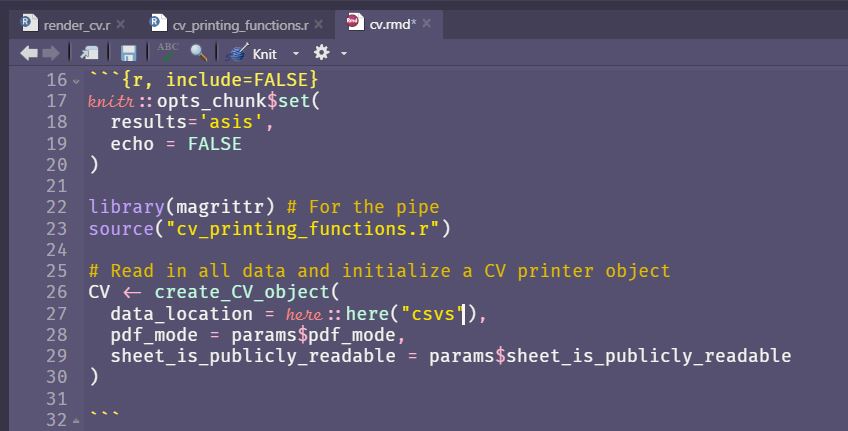
data_location argument in the create_CV_object() function
Render your CV
Finally you’re all set to be able to render your CV!
To do this you render_cv.r file.
source('C:/Work/Learning/madiba-cv/render_cv.r')If you want to host the html version of your CV as a static site (say on GitHub Pages, or Netlify) you should make one amendment in this file.
Change the output file in your HTML rendering call from cv.html to index.html.
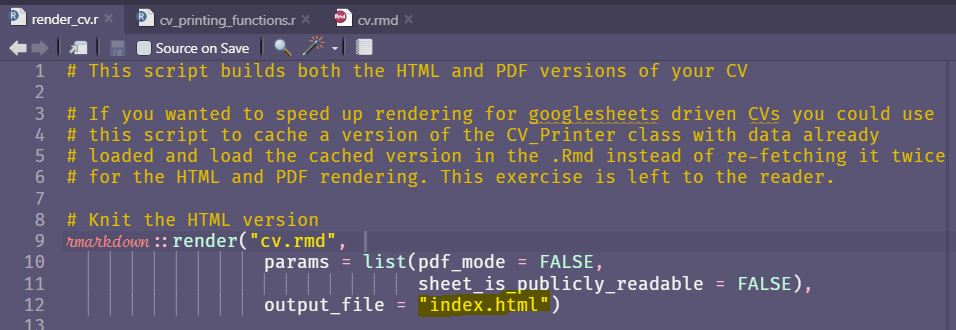
output_file argument to be index.html
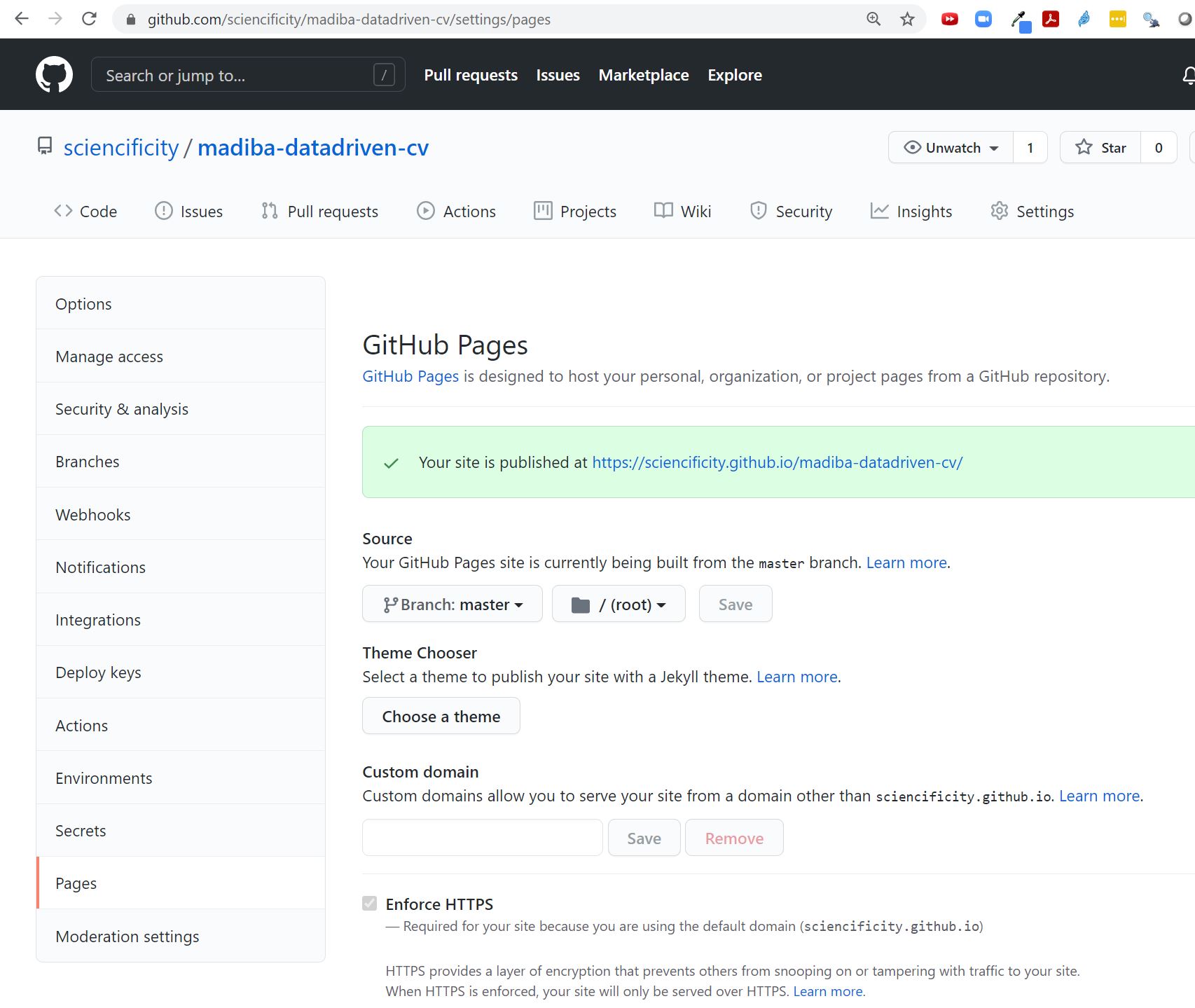
Host Online
- Push your files to GitHub.
- In the
SettingsPage navigate toGitHub Pagessection and fill in the source as your branch, and the folder as root. - Your site will be published with a URL (it may take a few minutes to render so try again after a few minutes if you experience a 404 error).
Appendices
- {datadrivencv} GitHub site as well as documentation.
- Nick’s blog post.
- Nick’s CV.
- Connecting to Google Sheets.
- Google Sheets Authentication, also {gargle}.
Mock CV Files
The mock CV source files can be found here.
The html finished product is here.
Packages used
In this post the main packages we used are the following:
library(datadrivencv)
library(googlesheets4)
library(pagedown)
library(magrittr)
library(readxl)
library(readr)
library(knitr)
library(glue)
library(gargle)
library(here)
Most of these are installed as part of the install of {datadrivencv}.